SCRAPY学习笔记(思维导图)
在学校进行科创项目时,由于需要用到 Scrapy 爬虫框架,花了一段时间自学,期间整理的思维导图记录在此。
一、关于 Scrapy
Scrapy 是一个 Python 爬虫框架,可以很方便地使用此框架编写爬虫并爬取解析网络数据,Scrapy 官网在这里。
安装 Scrapy:
1.使用 Anaconda 进行安装
在 Windows 平台安装 Scrapy 需要使用 Anaconda Distribution,因为如果直接使用自己安装的 Python PIP 包管理器进行安装可能会导致依赖组件的编译问题(可能需要特定的C++运行库),使用 Anaconda 进行安装的步骤:
- 安装 Anaconda Distribution;
- 打开 Anaconda Prompt;
- 执行命令 conda install -c conda-forge scrapy;
- 等待安装完成即可。
2.使用 pip 包管理器进行安装
使用虚拟环境或者系统 Python 命令行安装 scrapy。
1 | |
或
1 | |
二、Scrapy 常用命令
startproject
在 Anaconda Prompt 中执行
1 | |
**用途:**创建项目(Project),即创建一个项目文件夹并生成项目中的文件架构。
crawl
在 Anaconda Prompt 中执行
1 | |
**用途:**启动一个编写好的爬虫,爬虫类中 name 属性的值为爬虫的名称(即以上
shell
在 Anaconda Prompt 中执行
1 | |
**用途:**以交互模式启动,抓取 URL 中的网页后提供交互式命令行供用户手动分析,一般用于设计爬虫时的网页元素分析。
三、Scrapy 部分组件思维导图
Scrapy Spider

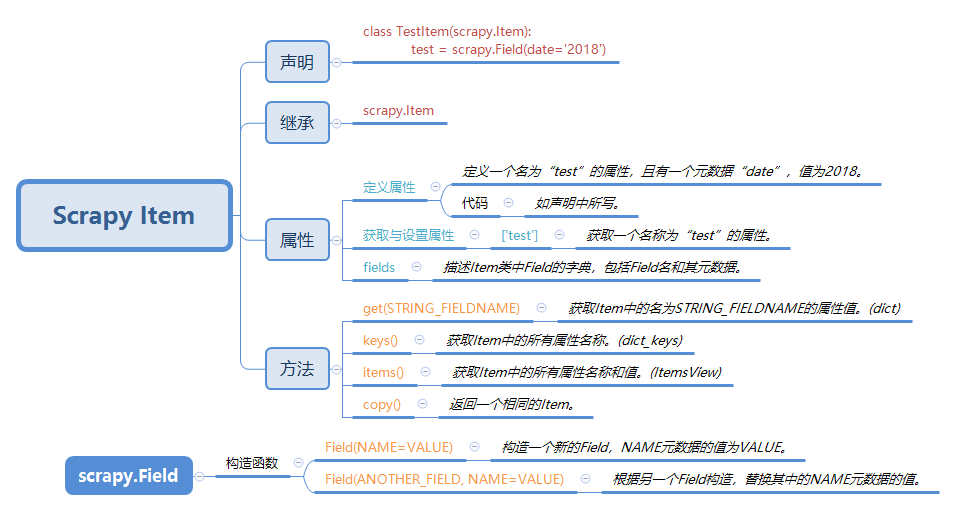
Scrapy Item
Scrapy ItemLoader

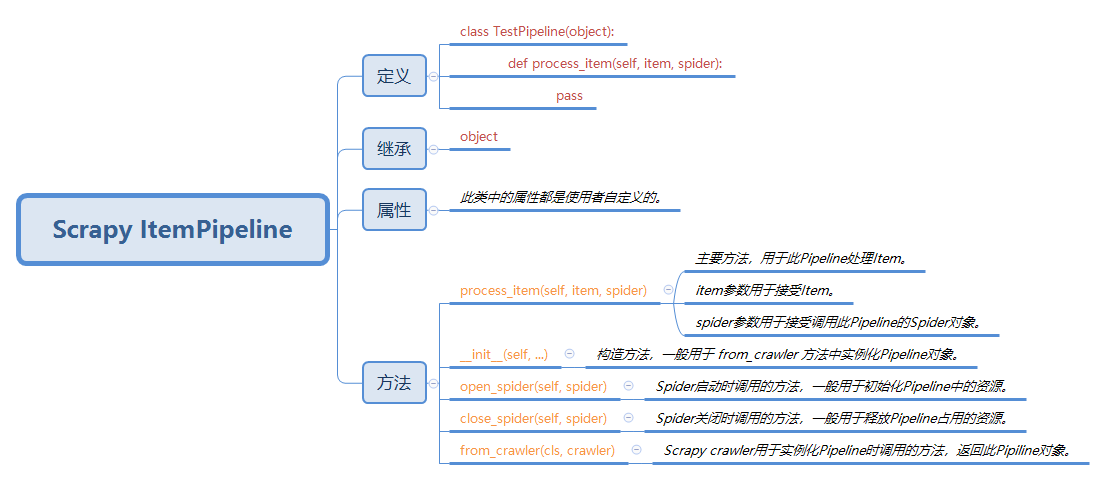
Scrapy ItemPipeline
Scrapy Request

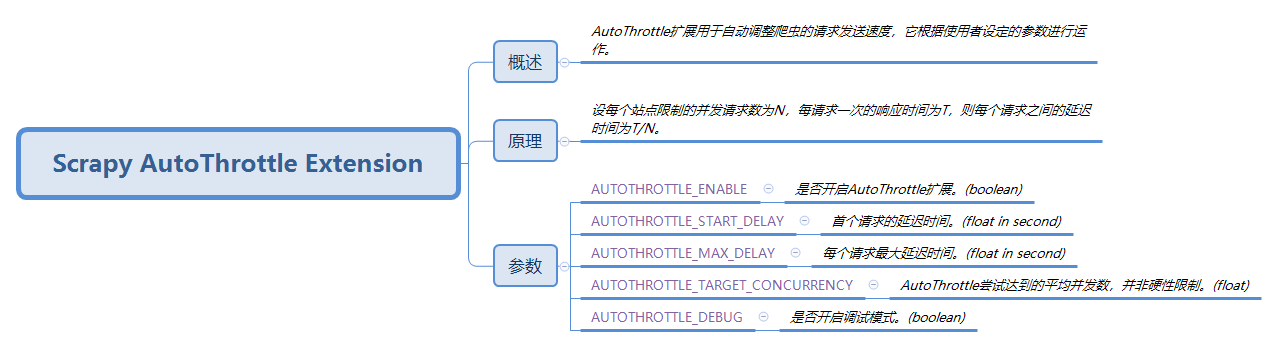
Scrapy AutoThrottle Extension
以上。
SCRAPY学习笔记(思维导图)
https://maphical.cn/2019/03/scrapy-study-note/